Как эксель считает коэффициент корреляции. Корреляционный анализ как сделать в excel
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:


После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.


В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:



Теперь стали видны и данные регрессионного анализа.
Коэффициент корреляции отражает степень взаимосвязи между двумя показателями. Всегда принимает значение от -1 до 1. Если коэффициент расположился около 0, то говорят об отсутствии связи между переменными.
Если значение близко к единице (от 0,9, например), то между наблюдаемыми объектами существует сильная прямая взаимосвязь. Если коэффициент близок к другой крайней точке диапазона (-1), то между переменными имеется сильная обратная взаимосвязь. Когда значение находится где-то посередине от 0 до 1 или от 0 до -1, то речь идет о слабой связи (прямой или обратной). Такую взаимосвязь обычно не учитывают: считается, что ее нет.
Расчет коэффициента корреляции в Excel
Рассмотрим на примере способы расчета коэффициента корреляции, особенности прямой и обратной взаимосвязи между переменными.
Значения показателей x и y:
Y – независимая переменная, x – зависимая. Необходимо найти силу (сильная / слабая) и направление (прямая / обратная) связи между ними. Формула коэффициента корреляции выглядит так:

Чтобы упростить ее понимание, разобьем на несколько несложных элементов.


Между переменными определяется сильная прямая связь.
Встроенная функция КОРРЕЛ позволяет избежать сложных расчетов. Рассчитаем коэффициент парной корреляции в Excel с ее помощью. Вызываем мастер функций. Находим нужную. Аргументы функции – массив значений y и массив значений х:

Покажем значения переменных на графике:

Видна сильная связь между y и х, т.к. линии идут практически параллельно друг другу. Взаимосвязь прямая: растет y – растет х, уменьшается y – уменьшается х.
Матрица парных коэффициентов корреляции в Excel
Корреляционная матрица представляет собой таблицу, на пересечении строк и столбцов которой находятся коэффициенты корреляции между соответствующими значениями. Имеет смысл ее строить для нескольких переменных.

Матрица коэффициентов корреляции в Excel строится с помощью инструмента «Корреляция» из пакета «Анализ данных».


Между значениями y и х1 обнаружена сильная прямая взаимосвязь. Между х1 и х2 имеется сильная обратная связь. Связь со значениями в столбце х3 практически отсутствует.
Для определения степени зависимости между несколькими показателями применяется множественные коэффициенты корреляции. Их затем сводят в отдельную таблицу, которая имеет название корреляционной матрицы. Наименованиями строк и столбцов такой матрицы являются названия параметров, зависимость которых друг от друга устанавливается. На пересечении строк и столбцов располагаются соответствующие коэффициенты корреляции. Давайте выясним, как можно провести подобный расчет с помощью инструментов Excel.
Принято следующим образом определять уровень взаимосвязи между различными показателями, в зависимости от коэффициента корреляции:
- 0 – 0,3 – связь отсутствует;
- 0,3 – 0,5 – связь слабая;
- 0,5 – 0,7 – средняя связь;
- 0,7 – 0,9 – высокая;
- 0,9 – 1 – очень сильная.
Если корреляционный коэффициент отрицательный, то это значит, что связь параметров обратная.
Для того, чтобы составить корреляционную матрицу в Экселе, используется один инструмент, входящий в пакет «Анализ данных» . Он так и называется – «Корреляция» . Давайте узнаем, как с помощью него можно вычислить показатели множественной корреляции.
Этап 1: активация пакета анализа
Сразу нужно сказать, что по умолчанию пакет «Анализ данных» отключен. Поэтому, прежде чем приступить к процедуре непосредственного вычисления коэффициентов корреляции, нужно его активировать. К сожалению, далеко не каждый пользователь знает, как это делать. Поэтому мы остановимся на данном вопросе.


После указанного действия пакет инструментов «Анализ данных» будет активирован.
Этап 2: расчет коэффициента
Теперь можно переходить непосредственно к расчету множественного коэффициента корреляции. Давайте на примере представленной ниже таблицы показателей производительности труда, фондовооруженности и энерговооруженности на различных предприятиях рассчитаем множественный коэффициент корреляции указанных факторов.


Этап 3: анализ полученного результата
Теперь давайте разберемся, как понимать тот результат, который мы получили в процессе обработки данных инструментом «Корреляция» в программе Excel.
Как видим из таблицы, коэффициент корреляции фондовооруженности (Столбец 2 ) и энерговооруженности (Столбец 1 ) составляет 0,92, что соответствует очень сильной взаимосвязи. Между производительностью труда (Столбец 3 ) и энерговооруженностью (Столбец 1 ) данный показатель равен 0,72, что является высокой степенью зависимости. Коэффициент корреляции между производительностью труда (Столбец 3 ) и фондовооруженностью (Столбец 2 ) равен 0,88, что тоже соответствует высокой степени зависимости. Таким образом, можно сказать, что зависимость между всеми изучаемыми факторами прослеживается довольно сильная.
Как видим, пакет «Анализ данных» в Экселе представляет собой очень удобный и довольно легкий в обращении инструмент для определения множественного коэффициента корреляции. С его же помощью можно производить расчет и обычной корреляции между двумя факторами.
Вычислим коэффициент корреляции и ковариацию для разных типов взаимосвязей случайных величин.
Коэффициент корреляции (критерий корреляции Пирсона, англ. Pearson Product Moment correlation coefficient) определяет степень линейной взаимосвязи между случайными величинами.
Как следует из определения, для вычисления коэффициента корреляции требуется знать распределение случайных величин Х и Y. Если распределения неизвестны, то для оценки коэффициента корреляции используется выборочный коэффициент корреляции r (еще он обозначается как R xy или r xy ) :

где S x – стандартное отклонение выборки случайной величины х, вычисляемое по формуле:

Как видно из формулы для расчета корреляции , знаменатель (произведение стандартных отклонений) просто нормирует числитель таким образом, что корреляция оказывается безразмерным числом от -1 до 1. Корреляция и ковариация предоставляют одну и туже информацию (если известны стандартные отклонения ), но корреляцией удобнее пользоваться, т.к. она является безразмерной величиной.
Рассчитать коэффициент корреляции и ковариацию выборки в MS EXCEL не представляет труда, так как для этого имеются специальные функции КОРРЕЛ() и КОВАР() . Гораздо сложнее разобраться, как интерпретировать полученные значения, большая часть статьи посвящена именно этому.
Теоретическое отступление
Напомним, что корреляционной связью называют статистическую связь, состоящую в том, что различным значениям одной переменной соответствуют различные средние значения другой (с изменением значения Х среднее значение Y изменяется закономерным образом). Предполагается, что обе переменные Х и Y являются случайными величинами и имеют некий случайный разброс относительно их среднего значения .
Примечание . Если случайную природу имеет только одна переменная, например, Y, а значения другой являются детерминированными (задаваемыми исследователем), то можно говорить только о регрессии.
Таким образом, например, при исследовании зависимости среднегодовой температуры нельзя говорить о корреляции температуры и года наблюдения и, соответственно, применять показатели корреляции с соответствующей их интерпретацией.
Корреляционная связь между переменными может возникнуть несколькими путями:
- Наличие причинной зависимости между переменными. Например, количество инвестиций в научные исследования (переменная Х) и количество полученных патентов (Y). Первая переменная выступает как независимая переменная (фактор) , вторая - зависимая переменная (результат) . Необходимо помнить, что зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
- Наличие сопряженности (общей причины). Например, с ростом организации растет фонд оплаты труда (ФОТ) и затраты на аренду помещений. Очевидно, что неправильно предполагать, что аренда помещений зависит от ФОТ. Обе этих переменных во многих случаях линейно зависят от количества персонала.
- Взаимовлияние переменных (при изменении одной, вторая переменная изменяется, и наоборот). При таком подходе допустимы две постановки задачи; любая переменная может выступать как в роли независимой переменной и в роли зависимой.
Таким образом, показатель корреляции показывает, насколько сильна линейная взаимосвязь между двумя факторами (если она есть), а регрессия позволяет прогнозировать один фактор на основе другого.
Корреляция , как и любой другой статистический показатель, при правильном применении может быть полезной, но она также имеет и ограничения по использованию. Если показывает четко выраженную линейную зависимость или полное отсутствие взаимосвязи, то корреляция замечательно это отразит. Но, если данные показывают нелинейную взаимосвязь (например, квадратичную), наличие отдельных групп значений или выбросов, то вычисленное значение коэффициента корреляции может ввести в заблуждение (см. файл примера ).
Корреляция близкая к 1 или -1 (т.е. близкая по модулю к 1) показывает сильную линейную взаимосвязь переменных, значение близкое к 0 показывает отсутствие взаимосвязи. Положительная корреляция означает, что с ростом одного показателя другой в среднем увеличивается, а при отрицательной – уменьшается.
Для вычисления коэффициента корреляции требуется, чтобы сопоставляемые переменные удовлетворяли следующим условиям:
- количество переменных должно быть равно двум;
- переменные должны быть количественными (например, частота, вес, цена). Вычисленное среднее значение этих переменных имеет понятный смысл: средняя цена или средний вес пациента. В отличие от количественных, качественные (номинальные) переменные принимают значения лишь из конечного набора категорий (например, пол или группа крови). Этим значениям условно сопоставлены числовые значения (например, женский пол – 1, а мужской – 2). Понятно, что в этом случае вычисление среднего значения , которое требуется для нахождения корреляции , некорректно, а значит некорректно и вычисление самой корреляции ;
- переменные должны быть случайными величинами и иметь .
Двумерные данные могут иметь различную структуру. Для работы с некоторыми из них требуются определенные подходы:
- Для данных с нелинейной связью корреляцию нужно использовать с осторожностью. Для некоторых задач бывает полезно преобразовать одну или обе переменных так, чтобы получить линейную взаимосвязь (для этого требуется сделать предположение о виде нелинейной связи, чтобы предложить нужный тип преобразования).
- С помощью диаграммы рассеяния у некоторых данных можно наблюдать неравную вариацию (разброс). Проблема неодинаковой вариации состоит в том, что места с высокой вариацией не только предоставляют наименее точную информацию, но и оказывают наибольшее влияние при расчете статистических показателей. Эту проблему также часто решают с помощью преобразования данных, например, с помощью логарифмирования.
- У некоторых данных можно наблюдать разделение на группы (clustering), что может свидетельствовать о необходимости разделения совокупности на части.
- Выброс (резко отклоняющееся значение) может исказить вычисленное значение коэффициента корреляции. Выброс может быть причиной случайности, ошибки при сборе данных или могут действительно отражать некую особенность взаимосвязи. Так как выброс сильно отклоняется от среднего значения, то он вносит большой вклад при расчете показателя. Часто расчет статистических показателей производят с и без учета выбросов.
Использование MS EXCEL для расчета корреляции
В качестве примера возьмем 2 переменные Х и Y и, соответственно, выборку состоящую из нескольких пар значений (Х i ; Y i). Для наглядности построим .

Примечание : Подробнее о построении диаграмм см. статью . В файле примера для построения диаграммы рассеяния использована , т.к. мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс). В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
Расчеты корреляции проведем для различных случаев взаимосвязи между переменными: линейной, квадратичной и при отсутствии связи .
Примечание : В файле примера можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В файле примера для построения диаграммы рассеяния в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.

Примечание : Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми.
Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ() . Также можно воспользоваться аналогичной функцией PEARSON() , которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления корреляции производятся функцией КОРРЕЛ() по вышеуказанным формулам, в файле примера приведено вычисление корреляции с помощью более подробных формул:
=КОВАРИАЦИЯ.Г(B28:B88;D28:D88)/СТАНДОТКЛОН.Г(B28:B88)/СТАНДОТКЛОН.Г(D28:D88)
=КОВАРИАЦИЯ.В(B28:B88;D28:D88)/СТАНДОТКЛОН.В(B28:B88)/СТАНДОТКЛОН.В(D28:D88)
Примечание : Квадрат коэффициента корреляции r равен коэффициенту детерминации R2, который вычисляется при построении линии регрессии с помощью функции КВПИРСОН() . Значение R2 также можно вывести на диаграмме рассеяния , построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку Макет , затем в группе Анализ нажмите кнопку Линия тренда и выберите Линейное приближение ). Подробнее о построении линии тренда см., например, в .

Использование MS EXCEL для расчета ковариации
Ковариация близка по смыслу с (также является мерой разброса) с тем отличием, что она определена для 2-х переменных, а дисперсия - для одной. Поэтому, cov(x;x)=VAR(x).

Для вычисления ковариации в MS EXCEL (начиная с версии 2010 года) используются функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() . В первом случае формула для вычисления аналогична вышеуказанной (окончание .Г обозначает Генеральная совокупность ), во втором – вместо множителя 1/n используется 1/(n-1), т.е. окончание .В обозначает Выборка .
Примечание : Функция КОВАР() , которая присутствует в MS EXCEL более ранних версий, аналогична функции КОВАРИАЦИЯ.Г() .
Примечание : Функции КОРРЕЛ() и КОВАР() в английской версии представлены как CORREL и COVAR. Функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() как COVARIANCE.P и COVARIANCE.S.
Дополнительные формулы для расчета ковариации :
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88-СРЗНАЧ(D28:D88)))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88;D28:D88)/СЧЁТ(D28:D88)-СРЗНАЧ(B28:B88)*СРЗНАЧ(D28:D88)
Эти формулы используют свойство ковариации :

Если переменные x и y независимые, то их ковариация равна 0. Если переменные не являются независимыми, то дисперсия их суммы равна:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
А дисперсия их разности равна
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
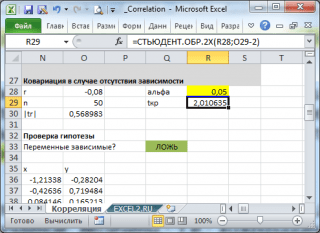
Оценка статистической значимости коэффициента корреляции
Для того чтобы проверить гипотезу, мы должны знать распределение случайной величины, т.е. коэффициента корреляции r. Обычно, проверку гипотезы осуществляют не для r, а для случайной величины t r:

которая имеет с n-2 степенями свободы.
Если вычисленное значение случайной величины |t r | больше, чем критическое значение t α,n-2 (α- заданный ), то нулевую гипотезу отклоняют (взаимосвязь величин является статистически значимой).
Надстройка Пакет анализа
В для вычисления ковариации и корреляции имеются одноименные инструменты анализа .

После вызова инструмента появляется диалоговое окно, которое содержит следующие поля:

- Входной интервал : нужно ввести ссылку на диапазон с исходными данными для 2-х переменных
- Группирование : как правило, исходные данные вводятся в 2 столбца
- Метки в первой строке : если установлена галочка, то Входной интервал должен содержать заголовки столбцов. Рекомендуется устанавливать галочку, чтобы результат работы Надстройки содержал информативные столбцы
- Выходной интервал : диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
Надстройка возвращает вычисленные значения корреляции и ковариации (для ковариации также вычисляются дисперсии обоих случайных величин).

Утилита, которая широко используется во многих компаниях и на предприятиях. Реалии таковы, что практически любой работник должен в той или иной мере владеть Экселем, так как эта программа применяется для решения очень широкого спектра задач. Работая с таблицами, нередко приходится определять, связаны ли между собой определённые переменные. Для этого используется так называемая корреляция. В этой статье мы подробно рассмотрим, как рассчитать коэффициент корреляции в Excel. Давайте разбираться. Поехали!
Начнём с того, что такое коэффициент корреляции вообще. Он показывает степень взаимосвязи между двумя элементами и всегда находится в диапазоне от -1 (сильная обратная взаимосвязь) до 1 (сильная прямая взаимосвязь). Если коэффициент равен 0, это говорит о том, что взаимосвязь между значениями отсутствует.
Теперь, разобравшись с теорией, перейдём к практике. Чтобы найти взаимосвязь между переменными и у, воспользуйтесь встроенной функцией Microsoft Excel «КОРРЕЛ». Для этого нажмите на кнопку мастера функций (она расположена рядом с полем для формул). В открывшемся окне выберите из списка функций «КОРРЕЛ». После этого задайте диапазон в полях «Массив1» и «Массив2». Например, для «Массив1» выделите значения у, а для «Массив2» выделите значения х. В итоге вы получите рассчитанный программой коэффициент корреляции.

Следующий способ будет актуален для студентов, от которых требуют найти зависимость по заданной формуле. Прежде всего, нужно знать средние значения переменных x и y. Для этого выделите значения переменной и воспользуйтесь функцией «СРЗНАЧ». Далее необходимо вычислить разницу между каждым x и x ср, и y ср. В выбранных ячейках напишите формулы x-x, y-. Не забудьте закрепить ячейки со средними значениями. Затем растяните формулу вниз, чтобы она применилась и к остальным числам.
Теперь, когда есть все необходимые данные, можно посчитать корреляцию. Перемножьте полученные разности таким образом: (x-x ср) * (y-y ср). После того как вы получите результат для каждой из переменных, просуммируйте полученные числа при помощи функции автосуммы. Таким образом рассчитывается числитель.
Теперь перейдём к знаменателю. Посчитанные разности нужно возвести в квадрат. Для этого в отдельной колонке введите формулы: (x-x ср) 2 и (y-y ср) 2 . Затем растяните формулы на весь диапазон. После, при помощи кнопки «Автосумма», найдите сумму по всем колонкам (для x и для y). Осталось перемножить найденные суммы и извлечь из них квадратный корень. Последний шаг - поделите числитель на знаменатель. Полученный результат и будет искомым коэффициентом корреляции.
Как видите, умея правильно работать с функциями Microsoft Excel , можно существенно упростить себе задачу расчёта непростых математических выражений. Благодаря средствам, реализованным в программе, вы без труда сделаете корреляционный анализ в Excel всего за пару минут, сэкономив время и силы. Пишите в комментариях, помогла ли вам статья разобраться в вопросе, спрашивайте обо всём, что заинтересовало вас по рассмотренной теме.





